機械学習の復習として個人的なノートとして書いていきます。
今回扱うのはアヤメデータです。
「アヤメ?」と思うかもしれませんが、機械学習をちょっとかじったことがある人であれば、一度は触れるデータです。なぜかというと、機械学習で有名なライブラリにサンプルデータとして付属しているからです。
というわけで進めていきます。
データを読み込む
from sklearn.datasets import load_iris
iris = load_iris()機械学習で有名なライブラリである「scikit-learn」にあるアヤメデータを読み込む関数をインポートし、変数irisにアヤメデータをセットします。
sklearn.datasetsには多くのサンプルデータが用意されています。(リンク)
Google先生に聞けば、いまやサンプルデータとして使えるものは数多ありますが、scikit-learnに付属するデータは色々なサイトや書籍、論文で使われることが多く、機械学習の勉強用には最適です。
sklearn.datasetsにある他のデータについても今後このブログで触れていければと思います。
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target機械学習のデータを扱うために必要なpandasというライブラリをインポートします。
そして、pandasのDataFrameというオブジェクトにアヤメデータを読み込みます。DataFrameは二次元のデータを取り扱うのに適したオブジェクトで多くの機械学習の処理では不可欠となります。
アヤメデータは少し特殊なので、説明変数と目的変数があらかじめ別々に提供されていますが、通常はCSV形式でデータ提供されることが多く、その場合は自分で説明変数と目的変数を必要に応じて分割する必要があります。
データの中身を確認する
display(df.head())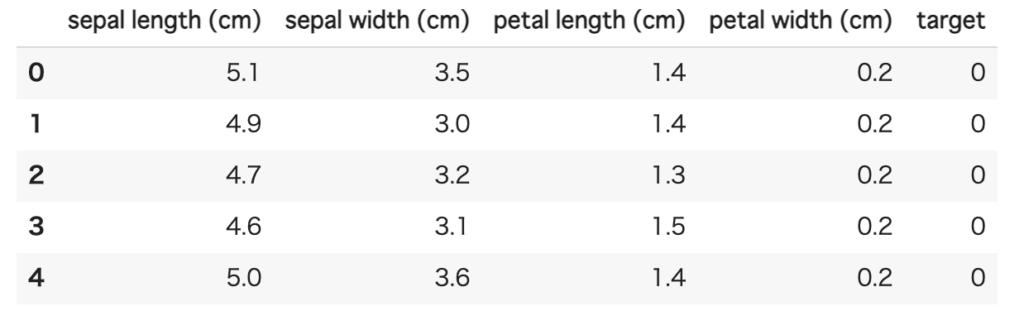
DataFrameにはhead関数というものがあり、データの先頭を返してくれます。
データの中身をちょっと見てみたい場合に使います。
デフォルトでは先頭5行分ですが、head関数の引数に数字を渡すことで、先頭からその数字分のデータを返してくれます。
display(df.info())
DataFrameにはinfo関数というものもあり、これはデータの件数や各項目の型&null有無、メモリ使用量を返してくれます。
display(df.describe())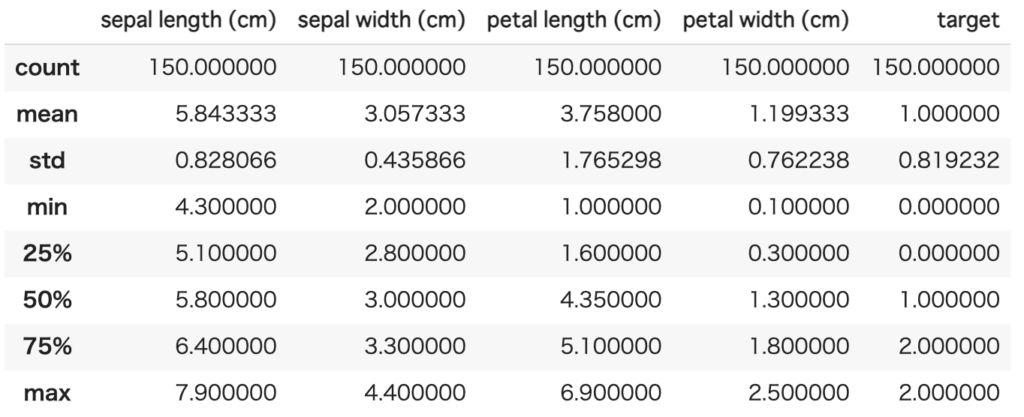
さらにDataFrameにはdescribe関数というものがあり、これはデータの統計量を返してくれます。
具体的には、件数、平均、標準偏差、最小、パーセンタイル、最大で、各項目の状況が把握できます。
データを可視化する
ここからはデータの状況をより把握するために、グラフ等を使って可視化していきます。
import seaborn as sns
%matplotlib inlineseabornとはデータを可視化するのに特化したライブラリです。
「%matplotlib inline」はJupyter Notebookでグラフを表示するために必要なおまじないです。
sns.pairplot(df, hue="target")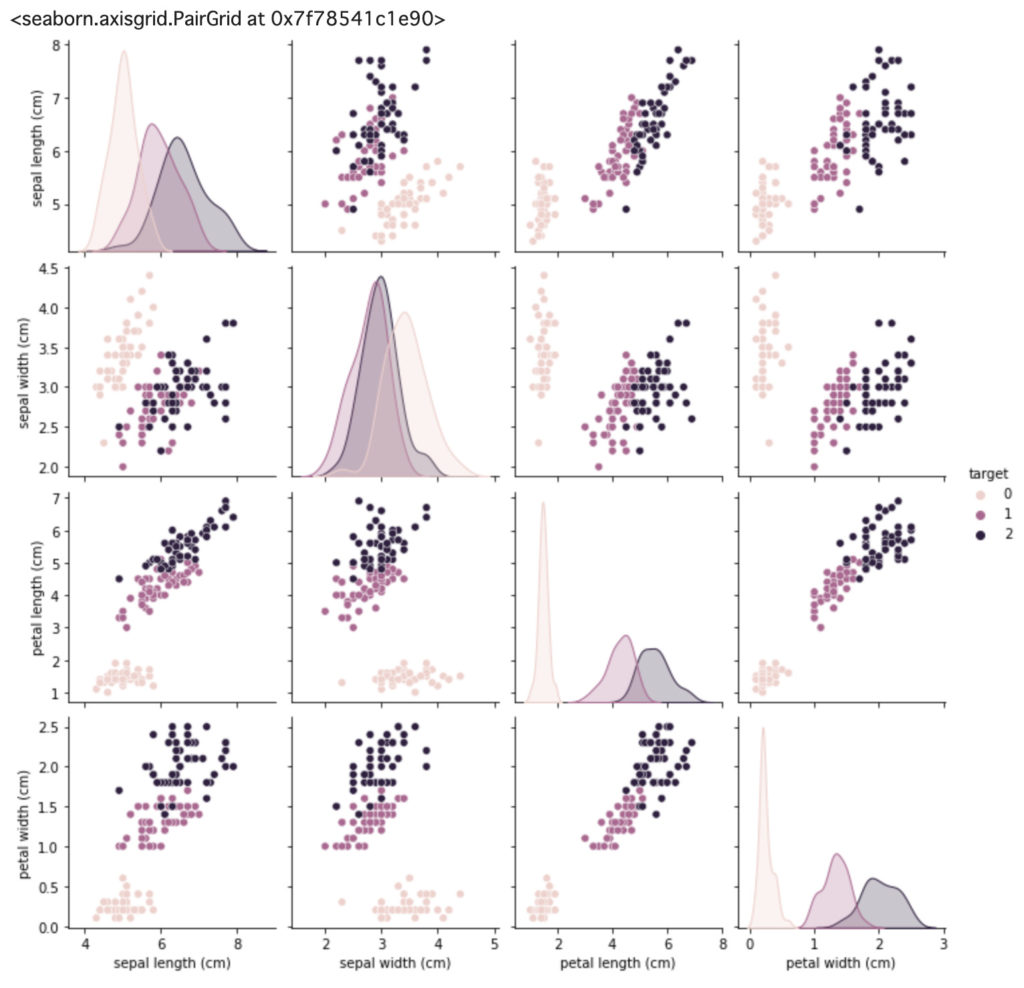
pairplot関数は項目間の散布図を出力してくれます。
ぱっと見で項目間の相関性が把握でき、データ分析する際に重宝します。
この散布図を見ると特定の項目ではかなりきれいに分類分けできそうな感じに見えます。
corr = df.corr()
sns.heatmap(corr, square=True, annot=True)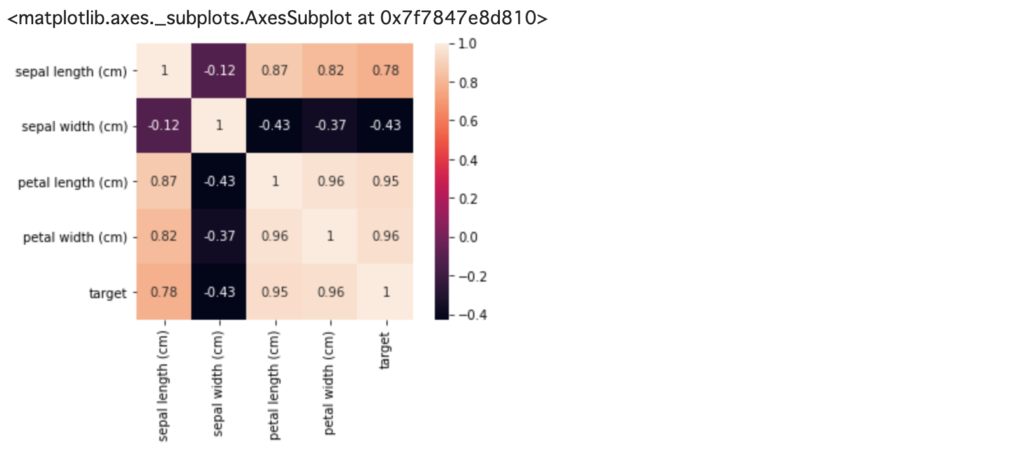
さきほどのpairplot関数では視覚的に項目間の相関関係を見ることができましたが、heatmap関数は定量的に相関関係を見る場合に使います。
ヒートマップの数字は相関係数になっており、絶対値が1に近いほど相関があります。
今回の場合では「sepal length」「petal length」「petal width」が分類(target)とかなり相関性があり、逆に「sepal width」はそこまで相関性はなさそうです。
これらの情報を用いて、どの項目に重みを置いて機械学習のアルゴリズムを適用するのか考えていく必要があります。
終わりに
今回はデータを読み込んで、中身をちょっと見てみるところまでやってみました。
次回は実際に機械学習のアルゴリズムを適用してみて、分類予測モデルを作ってみたいと思います。