ディープラーニングの歴史を振り返ってみようと思い、前回のVGG16に続いてResNetについて自分なりに整理します。
現在私がPyTorchの勉強をしているので、ここから先のコードはPyTorchベースとなる点、ご了承下さい。
元となる論文はこちらですので、詳細が気になる方はぜひ一読してみてください。
ResNetの構造を理解するために、PyTorchでの実装を見てみます。
class ResNet(nn.Module):
def __init__(self, block: Type[Union[BasicBlock, Bottleneck]], layers: List[int], num_classes: int = 1000, zero_init_residual: bool = False, groups: int = 1, width_per_group: int = 64, replace_stride_with_dilation: Optional[List[bool]] = None, norm_layer: Optional[Callable[..., nn.Module]] = None) -> None:
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(self, block: Type[Union[BasicBlock, Bottleneck]], planes: int, blocks: int, stride: int = 1, dilate: bool = False) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(conv1x1(self.inplanes, planes * block.expansion, stride), norm_layer(planes * block.expansion))
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups, base_width=self.base_width, dilation=self.dilation, norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def _resnet(arch: str, block: Type[Union[BasicBlock, Bottleneck]], layers: List[int], pretrained: bool, progress: bool, **kwargs: Any) -> ResNet:
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
model.load_state_dict(state_dict)
return model
def resnet18(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress ,**kwargs)
def resnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress ,**kwargs)
def resnet50(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
def resnet101(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
def resnet152(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress, **kwargs)ResNetには複数のパターンがあり、上記ソース最後に記述がありますが、表にするとこのようになります。

論文ではResNetには18層から152層までの5種類が紹介されており、前回紹介したVGGに比べて極めて層が厚くなっています。これはResNetの特徴である残差学習によって層を厚くした際に発生する勾配消失を抑えることができるからです。
また、ResNet34とResNet50の間に一つ区切りがあり、使っているブロックの種類が異なります。ResNet34まではBasicBlock、ResNet50からはBottleneckです。
こちらもソースと図を見ると、構造の違いがわかります。
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(self, inplanes: int, planes: int, stride: int = 1, downsample: Optional[nn.Module] = None, groups: int = 1, base_width: int = 64, dilation: int = 1, norm_layer: Optional[Callable[..., nn.Module]] = None) -> None:
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion: int = 4
def __init__(self, inplanes: int, planes: int, stride: int = 1, downsample: Optional[nn.Module] = None, groups: int = 1, base_width: int = 64, dilation: int = 1, norm_layer: Optional[Callable[..., nn.Module]] = None) -> None:
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
両者は計算コストが同じですが、Bottleneckの方がより層を厚くすることが可能となります。
これらの改良によりResNetはVGG16を大幅に超える精度を出すことができました。
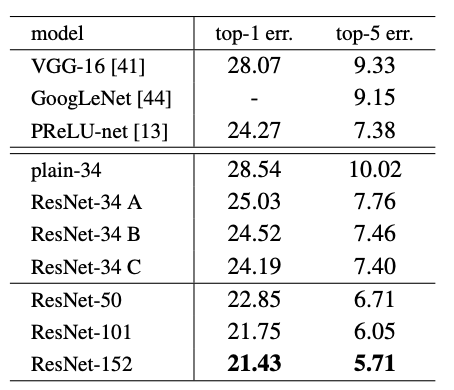
まとめ
ResNetは現在でも至るところで発生するネットワークですので、詳細を理解できて良かったです。次はさらにResNetよりも進化したモデルについて調べてみようと思います。