ディープラーニングの歴史を振り返ってみようと思い、前回のResNetに続いてEfficientNetについて自分なりに整理します。
現在私がPyTorchの勉強をしているので、ここから先のコードはPyTorchベースとなる点、ご了承下さい。
元となる論文はこちらですので、詳細が気になる方はぜひ一読してみてください。
EfficientNetの構造を理解するために、PyTorchでの実装を見てみます。今回は公式のリポジトリではなくこちらのリポジトリを参考にしております。
class EfficientNet(nn.Module):
def __init__(self, blocks_args=None, global_params=None):
super().__init__()
assert isinstance(blocks_args, list), 'blocks_args should be a list'
assert len(blocks_args) > 0, 'block args must be greater than 0'
self._global_params = global_params
self._blocks_args = blocks_args
# Batch norm parameters
bn_mom = 1 - self._global_params.batch_norm_momentum
bn_eps = self._global_params.batch_norm_epsilon
# Get stem static or dynamic convolution depending on image size
image_size = global_params.image_size
Conv2d = get_same_padding_conv2d(image_size=image_size)
# Stem
in_channels = 3 # rgb
out_channels = round_filters(32, self._global_params) # number of output channels
self._conv_stem = Conv2d(in_channels, out_channels, kernel_size=3, stride=2, bias=False)
self._bn0 = nn.BatchNorm2d(num_features=out_channels, momentum=bn_mom, eps=bn_eps)
image_size = calculate_output_image_size(image_size, 2)
# Build blocks
self._blocks = nn.ModuleList([])
for block_args in self._blocks_args:
# Update block input and output filters based on depth multiplier.
block_args = block_args._replace(
input_filters=round_filters(block_args.input_filters, self._global_params),
output_filters=round_filters(block_args.output_filters, self._global_params),
num_repeat=round_repeats(block_args.num_repeat, self._global_params)
)
# The first block needs to take care of stride and filter size increase.
self._blocks.append(MBConvBlock(block_args, self._global_params, image_size=image_size))
image_size = calculate_output_image_size(image_size, block_args.stride)
if block_args.num_repeat > 1: # modify block_args to keep same output size
block_args = block_args._replace(input_filters=block_args.output_filters, stride=1)
for _ in range(block_args.num_repeat - 1):
self._blocks.append(MBConvBlock(block_args, self._global_params, image_size=image_size))
# image_size = calculate_output_image_size(image_size, block_args.stride) # stride = 1
# Head
in_channels = block_args.output_filters # output of final block
out_channels = round_filters(1280, self._global_params)
Conv2d = get_same_padding_conv2d(image_size=image_size)
self._conv_head = Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self._bn1 = nn.BatchNorm2d(num_features=out_channels, momentum=bn_mom, eps=bn_eps)
# Final linear layer
self._avg_pooling = nn.AdaptiveAvgPool2d(1)
self._dropout = nn.Dropout(self._global_params.dropout_rate)
self._fc = nn.Linear(out_channels, self._global_params.num_classes)
self._swish = MemoryEfficientSwish()
def forward(self, inputs):
# Convolution layers
x = self.extract_features(inputs)
# Pooling and final linear layer
x = self._avg_pooling(x)
if self._global_params.include_top:
x = x.flatten(start_dim=1)
x = self._dropout(x)
x = self._fc(x)
return x
@classmethod
def from_name(cls, model_name, in_channels=3, **override_params):
cls._check_model_name_is_valid(model_name)
blocks_args, global_params = get_model_params(model_name, override_params)
model = cls(blocks_args, global_params)
model._change_in_channels(in_channels)
return model
@classmethod
def from_pretrained(cls, model_name, weights_path=None, advprop=False, in_channels=3, num_classes=1000, **override_params):
model = cls.from_name(model_name, num_classes=num_classes, **override_params)
load_pretrained_weights(model, model_name, weights_path=weights_path, load_fc=(num_classes == 1000), advprop=advprop)
model._change_in_channels(in_channels)
return modeldef efficientnet_params(model_name):
params_dict = {
# Coefficients: width,depth,res,dropout
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
'efficientnet-b8': (2.2, 3.6, 672, 0.5),
'efficientnet-l2': (4.3, 5.3, 800, 0.5),
}
return params_dict[model_name]
def efficientnet(width_coefficient=None, depth_coefficient=None, image_size=None, dropout_rate=0.2, drop_connect_rate=0.2, num_classes=1000, include_top=True):
blocks_args = [
'r1_k3_s11_e1_i32_o16_se0.25',
'r2_k3_s22_e6_i16_o24_se0.25',
'r2_k5_s22_e6_i24_o40_se0.25',
'r3_k3_s22_e6_i40_o80_se0.25',
'r3_k5_s11_e6_i80_o112_se0.25',
'r4_k5_s22_e6_i112_o192_se0.25',
'r1_k3_s11_e6_i192_o320_se0.25',
]
blocks_args = BlockDecoder.decode(blocks_args)
global_params = GlobalParams(
width_coefficient=width_coefficient,
depth_coefficient=depth_coefficient,
image_size=image_size,
dropout_rate=dropout_rate,
num_classes=num_classes,
batch_norm_momentum=0.99,
batch_norm_epsilon=1e-3,
drop_connect_rate=drop_connect_rate,
depth_divisor=8,
min_depth=None,
include_top=include_top,
)
return blocks_args, global_params
def get_model_params(model_name, override_params):
if model_name.startswith('efficientnet'):
w, d, s, p = efficientnet_params(model_name)
# note: all models have drop connect rate = 0.2
blocks_args, global_params = efficientnet(width_coefficient=w, depth_coefficient=d, dropout_rate=p, image_size=s)
else:
raise NotImplementedError('model name is not pre-defined: {}'.format(model_name))
if override_params:
# ValueError will be raised here if override_params has fields not included in global_params.
global_params = global_params._replace(**override_params)
return blocks_args, global_paramsEfficientNetはGoogleの研究者が考えたネットワーク構造で、CNNの最適な構造を模索しているうちに、CNNの精度を上げるには「depth」「width」「image size」という3つのパラメータを増やせばいいのではという結論に至り、誕生しました。
発想はとても単純なものですが、これにより既存のネットワークモデルの精度を上回り、かつ計算コストを小さくすることに成功しました。(下のグラフ参照)
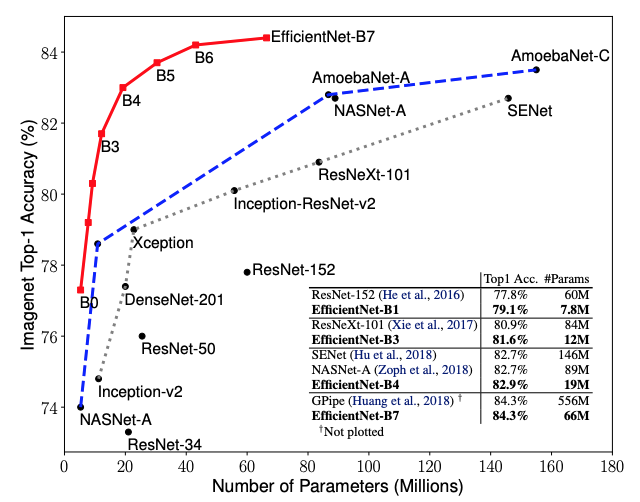
EfficientNetには8パターンのネットワーク構造がありますが、これについてはまず基礎となるEfficientNet-B0のパラメータの組み合わせを探索し、その後B1〜B7については、そのパラメータを一定数乗してパラメータを決めました。これについてはB1〜B7も独自にパラメータの組み合わせを探索できなくはなかったですが、計算コストが膨大になるため、先の手法を取ったようです。
先のソースコードのutils.pyのefficientnet_params関数にその3つのパラメータのパターンが設定されており、実装の上では肝になるかと思います。
以下が既存のネットワーク構造との比較ですが、その差は歴然ですね・・・
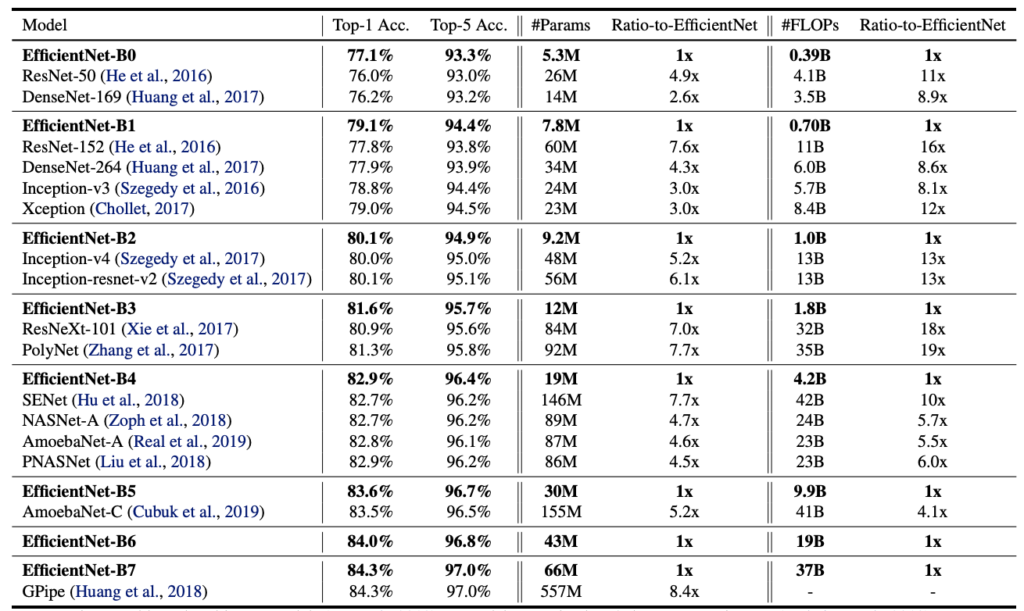
EfficientNetは現在KaggleでTOPクラスで使用されており、AI界隈への貢献は素晴らしいものがあります。繰り返しますが、わかってしまえば単純な発想ですが、ここに至ったGoogleの研究者は改めてスゴイと思います。
まとめ
EfficientNetは現在でKaggleで最も使われているネットワークですので、改めて構造の詳細を理解できて良かったです。ネットワーク構造についてはある程度古いものから最新のものまで把握できたので、次回は手法について調べてみようかと思います!