ディープラーニングの歴史を振り返ってみようと思い、第3次AIブームの初期に登場したAlexNetについて自分なりに整理します。
現在私がPyTorchの勉強をしているので、ここから先のコードはPyTorchベースとなる点、ご了承下さい。
元となる論文はこちらですので、詳細が気になる方はぜひ一読してみてください。
AlexNetの構造を理解するために、PyTorchでの実装を見てみます。
the class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x図で表すとこのようになります。
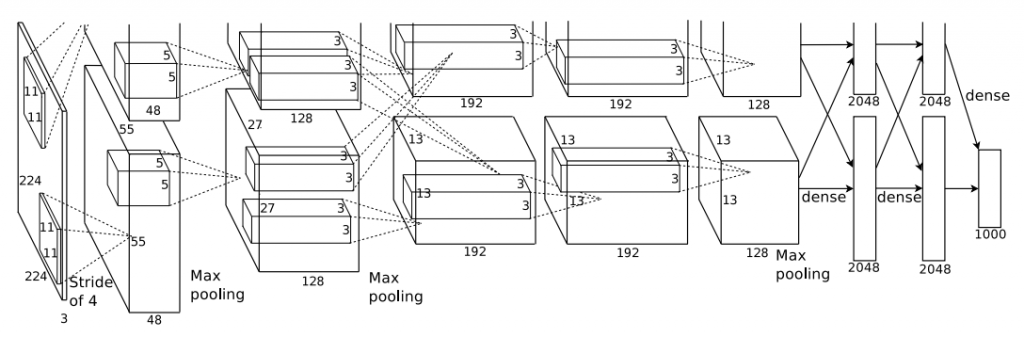
ソースコードと図からわかる通り、5枚の畳み込み層と3枚の全結合層から構成されています。
ちなみに畳み込み層と全結合層の間にある「AdaptiveAvgPool2d」は入力のサイズが何であれ出力のサイズを$(6 \times 6)$に合わせる役割となっています。入力画像のサイズが$(224 \times 224)$であれば畳み込み層を通過した時点で$(6 \times 6)$のはずですが、入力画像のサイズが異なる場合でも対応できるようになっています。
AlexNetの特徴として次の6つがあります。
- ReLu関数
- マルチGPU
- Local Response Normalization(局所応答正規化、LRN)
- Overlapping Pooling
- Data Augmentation(データ拡張)
- Dropout(ドロップアウト)
このうちのいくつかについて簡単に紹介します。
ReLu関数
活性化関数の一種で、かつてディープラーニングの大きな課題であった勾配消失問題を解消する突破口となったもので、直近では亜種はあれど活性化関数のデファクトスタンダードとなっている。
マルチGPU
GTX 580(メモリ3GB)というディープラーニングの学習を回す環境としては今では考えられないくらい弱々のGPUですが、そのスペックの低さをカバーするためにGPU2枚で学習させられるように工夫していた。
Data Augmentation
ディープラーニングの学習において、いかに大量で多様なデータを入力として与るか鍵である。しかし、データが多くない場合に1枚の画像に対して様々な加工(回転、反転、切り出し等)を行うことで、データ不足を補う手法。もちろん現在でも使われている手法。
Dropout
意図的に一定の確率でニューロンを不活性化することで、モデルの汎化性能を向上させる手法。こちらももちろん現在でも使われている手法。
まとめ
現在ではAlexNetよりも複雑で高い精度を出すモデルは数多とあるが、改めて振り返ってみることで得るものがある気がしました。次はAlexNetよりも少しだけ進化したモデルについて調べてみようと思います。